


한줄 요약
PASS/FAIL 기준을 세워두고 실제로 Ralph Loop를 돌려봤습니다. 54개 세션이 자동 실행되었고, 예상과 다른 교훈들을 얻었습니다. 그리고 구글 문서로 옮기는 과정에서 진짜 고통이 시작됐습니다.
이전 글 요약
Ralph Wiggum Loop로 초기창업패키지 사업 계획서 작성하기 - 1/2
[1편]에서 다뤘던 내용을 간단히 정리하면:
작년에 ChatGPT로 제안서 작성 시도 → 실패
올해는 Claude Code CLI + Task 단위 쪼개기 + Ralph Loop 전략
딥테크 기준이 모호해서 실제 선정 사례에서 역추론
20개 서브태스크로 세분화하고 각각 PASS/FAIL 기준 정의
"다음에는 실제로 Ralph Loop를 돌려볼 예정"
이번 글에서는 실제로 돌려본 결과와 그 과정에서 배운 것들을 공유합니다.
1. Ralph Loop 실제 실행: 54개 세션의 향연
run-tasks.sh 자동 실행
PASS/FAIL 기준을 정의해둔 Task들을 자동으로 실행하는 bash 스크립트(run-tasks.sh)를 만들었습니다. 구조는 단순합니다:
1. progress.txt를 읽어서 "미시작" 상태인 Task를 찾는다
2. 해당 Task에 대응하는 프롬프트를 plan-write-up.md에서 추출
3. claude -p --model opus --dangerously-skip-permissions --print 로 실행
4. 결과를 파일로 저장하고 progress.txt 상태 업데이트
5. 다음 Task로 넘어감
이걸 한 번 돌리면, 사람 개입 없이 여러 Task가 연속 실행됩니다.
실행 결과
Day 5-6에 걸쳐 총 54개 세션이 자동 실행되었습니다.
완료된 Task 목록:
Task 0.1 (분석): 챕터별 핵심 포인트, 고득점 전략, 딥테크 3요소 핵심 논리 정리
Task 1.1~1.3 + 1.R (1장 문제인식): 기업의 AI 전환 수요 폭발, 3가지 실패 지점, 기존 대안 비교표
Task 2.1~2.5 + 2.R (2장 실현가능성): CurateBot 서비스 개요, 딥테크 3요소, 차별점, 개발 로드맵, 사업비 계획
Task 3.1~3.4 + 3.R (3장 성장전략): TAM/SAM/SOM, GTM 전략, 확장 계획, IP 전략
생성된 파일:
draft/ch1-problem.md
draft/ch2-solution.md
draft/ch3-scaleup.md
한 번 돌아갈 때 약 30분 정도 걸렸던 것 같아요.
2. 예상과 달랐던 점들
교훈 1: 전체 한 번에 돌리는 것보다 섹션별로 쓰고 리뷰하는 게 나았다
처음에는 "20개 Task를 한 번에 쭉 돌리면 아침에 완성본이 나오겠지"라고 기대했습니다.
결과적으로 초안은 나왔지만, 내가 원하는 방향과 다른 부분이 많았습니다.
왜냐하면:
AI가 쓰다 보면 아이디어가 생기거나, 방향이 틀어지는 경우가 있음 - 예를 들면 불필요한 것이 추가되고 이걸 설명하기 위해서 계속 늘어남
그런데 한 번에 쭉 돌리면 중간에 방향 수정이 안 됨
결국 완성된 초안을 읽고 → 수정하고 → 다시 돌리는 작업이 필요했음
더 나은 방식:
섹션 1개 쓰기 → 리뷰 → 수정 → 다음 섹션 쓰기 → ...
이렇게 하면 중간중간 방향을 잡아줄 수 있습니다. Ralph Loop의 "성공할 때까지 반복"은 코딩에서는 테스트 통과 여부로 판단 가능하지만, 글쓰기에서는 "성공"의 기준이 내 머릿속에만 있기 때문입니다.
교훈 2: 글 쓰면서 생각이 정리된다
AI에게 시키기 전에 내가 뭘 원하는지 완벽히 알고 있어야 한다고 생각했습니다.
그런데 실제로 해보니, AI가 쓴 초안을 읽으면서 내 생각이 정리되는 경우가 많았습니다.
"아, 이렇게 쓰면 안 되겠다. 이 부분은 더 강조해야 하고, 저 부분은 빼야겠다."
이런 깨달음은 AI가 일단 뭔가를 써줘야 생기는 것입니다. 빈 페이지를 보고는 절대 안 떠오릅니다.
결론: AI와 글쓰기도 "생각을 정리하는 과정"입니다. AI가 대신 써주는 게 아니라, AI가 써준 걸 보면서 내가 뭘 원하는지 알게 되는 협업입니다.
교훈 3: 리서치는 아웃라인 단계에서 했어야 했다
처음 계획은 이랬습니다:
아웃라인 잡기
각 챕터 쓰면서 필요하면 리서치 (이걸 서브에이전트 여러개 만들어서 진행)
그런데 이게 문제였습니다. 챕터마다 AI가 리서치를 하니까:
매번 다른 출처, 다른 숫자가 나옴
앞 챕터와 뒤 챕터의 통계가 안 맞는 경우 발생
토큰 소모량 폭발 (같은 리서치를 여러 번 반복)
더 나은 방식:
아웃라인 단계에서 필요한 리서치를 미리 다 해놓고,
그 리서치 결과를 참조 파일로 만들어서
각 챕터 쓸 때 그 파일만 참조하게 함
이렇게 하면 일관성도 유지되고, 토큰도 아낍니다.
교훈 4: 토큰 한계와의 싸움
제안서 전체가 약 15페이지(A4 기준)입니다. 이걸 한 번에 리뷰 맡기려면?
Claude의 경우 약 25,000 토큰이 최대인데, 이게 대략 A4 15~20장 정도입니다. 딱 맞거나 조금 부족합니다.
해결책:
각 챕터를 요약본 + 원문 조합으로 리뷰 요청
또는 Gemini CLI 사용 (더 긴 컨텍스트 지원)
실제로 중요한 리뷰는 Gemini를 병행해서 받았습니다.
3. 서브에이전트 병렬 리뷰의 위력
Ralph Loop의 핵심 장점 중 하나는 자동화된 리뷰입니다.
각 챕터(ch1, ch2, ch3)를 다 쓴 후 Task X.R (리뷰 태스크)를 실행하면:
서브에이전트 3개가 병렬로 검토:
1. 내용 품질 검토 에이전트
2. 형식/구조 검토 에이전트
3. 딥테크 요건 검토 에이전트
이 세 에이전트가 각자의 관점에서 문제점을 지적하고, 그걸 종합해서 수정사항 목록을 만들어줍니다.
실제로 받은 피드백 예시:
❌ KPI 수치 목표가 없음
guide-proposal 권고: "누락률 X%→Y%", "완주율 A%→B%", "근거 포함률 C%" 등 정량 목표 필수
현재: "누락률, 완주율, 근거 포함률, 원가로 측정"이라고만 서술 → 현재 수치 + 목표 수치를 반드시 명시
❌ 마일스톤과 비목의 1:1 매칭 없음
guide-proposal: "무엇을 만들기 위해 어떤 비목이 필요한지가 읽히게"
현재: 비목별로 "어떤 산출물을 위한 것인지" 연결 없음
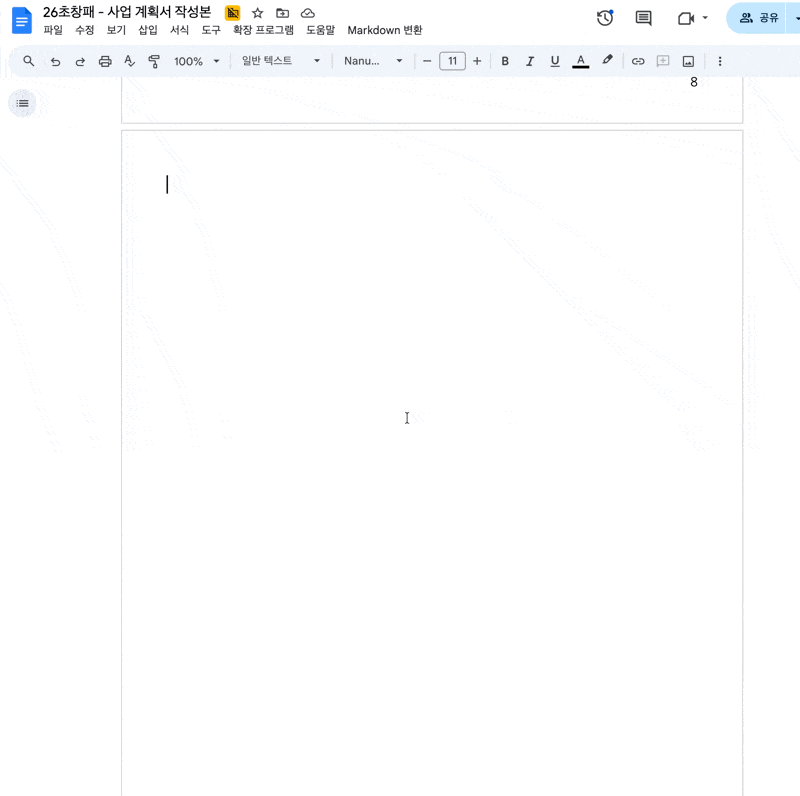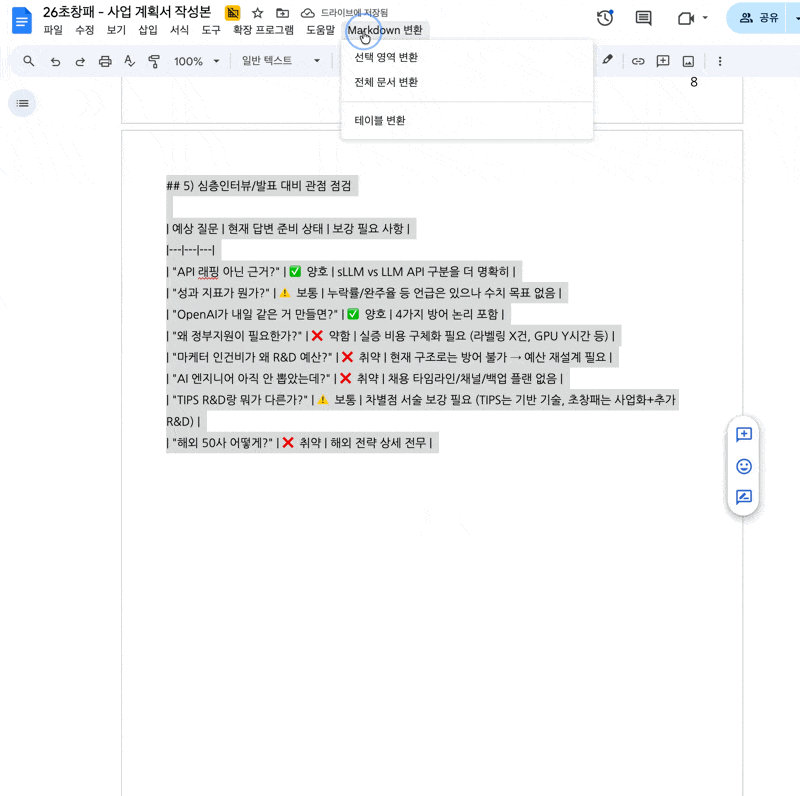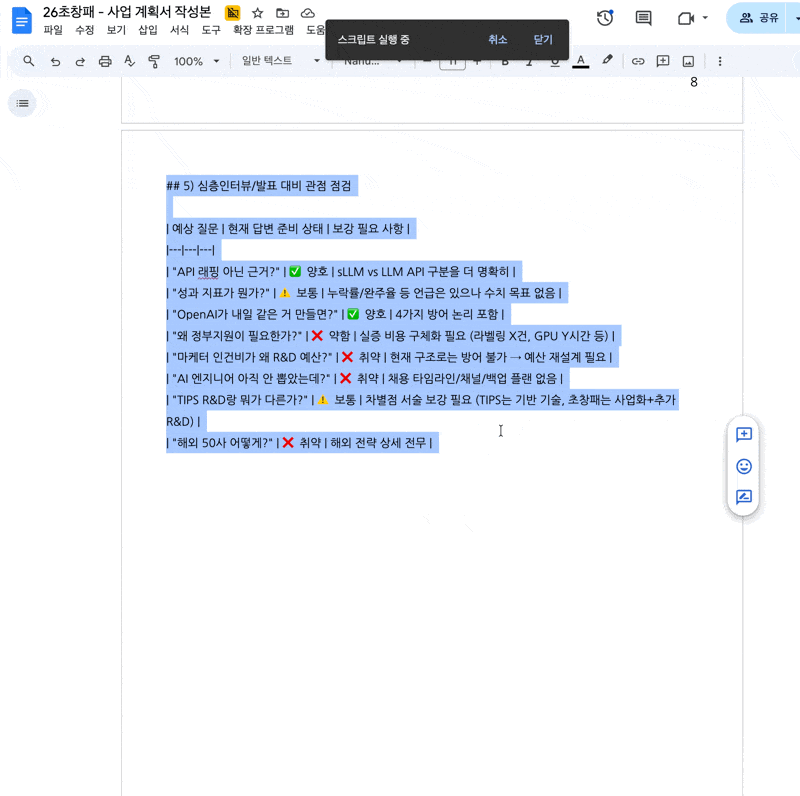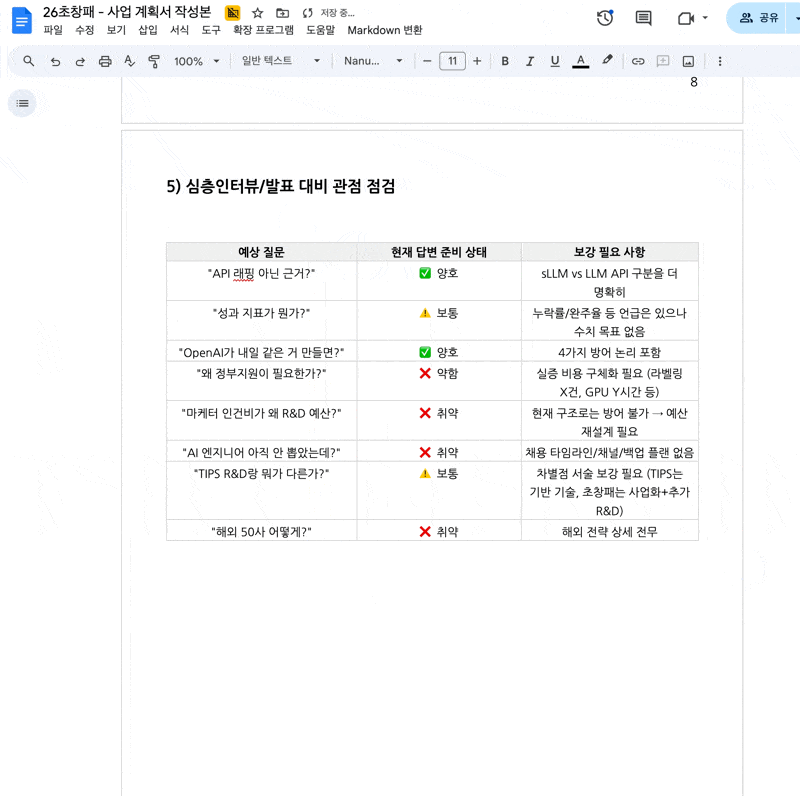
5) 심층인터뷰/발표 대비 관점 점검
예상 질문
현재 답변 준비 상태
보강 필요 사항
"API 래핑 아닌 근거?"
✅ 양호
sLLM vs LLM API 구분을 더 명확히
"성과 지표가 뭔가?"
⚠️ 보통
누락률/완주율 등 언급은 있으나 수치 목표 없음
"OpenAI가 내일 같은 거 만들면?"
✅ 양호
4가지 방어 논리 포함
"왜 정부지원이 필요한가?"
❌ 약함
실증 비용 구체화 필요 (라벨링 X건, GPU Y시간 등)
"마케터 인건비가 왜 R&D 예산?"
❌ 취약
현재 구조로는 방어 불가 → 예산 재설계 필요
"AI 엔지니어 아직 안 뽑았는데?"
❌ 취약
채용 타임라인/채널/백업 플랜 없음
"TIPS R&D랑 뭐가 다른가?"
⚠️ 보통
차별점 서술 보강 필요 (TIPS는 기반 기술, 초창패는 사업화+추가 R&D)
"해외 50사 어떻게?"
❌ 취약
해외 전략 상세 전무
이런 피드백은 내가 놓치기 쉬운 부분을 잡아줍니다. 특히 정부과제는 "잘 쓰는 것"보다 "트집 안 잡히게 쓰는 것"이 중요한데, 작성 가이드에 한줄이나 몇 단어 나와서 빠뜨린 KPI를 단계별로 명시하라는 것, 마일스톤과 사업비의 비목, 그리고 마일스톤과 그 마일스톤 각각의 담당자가 팀 구성에서 지정되어야 하는 것, 이런 것들은 쉽게 추가할 수 있지만 없는 경우, 트집 잡힐 수 있는 부분이었는데, AI 리뷰가 이런 세세한 부분을 챙겨줬습니다.
체감 효능감:
"나는 사소하게 생각하지만, 평가 기준에 있어서 놓치기 쉬운 것들을 잘 챙겨준다."
다만 시간이 부족해서 피드백을 다 반영하지는 못했습니다. 마감이 코앞이었거든요.
4. 구글 문서로 옮기기: 진짜 고통의 시작
사업계획서를 마크다운으로 쓴 이유는 AI가 쉽게 읽고 쓸 수 있어서입니다.
그런데 최종 제출은 구글 문서(Google Docs) 또는 워드(Word) 형식이어야 합니다.
문제 1: 불릿 리스트 스타일
마크다운의 불릿 리스트(-)가 구글 문서로 옮겨지면 기본 스타일로 바뀝니다. 폰트, 크기, 들여쓰기가 다 제각각.
해결책으로 Google Apps Script를 만들었습니다:
마크다운 불릿 레벨에 따라 폰트 크기 차등 적용 (레벨0: 13pt, 레벨1: 12pt, ...)
Nanum Gothic 폰트 통일
레벨0만 볼드, 나머지는 일반체
이 스크립트를 다듬는 데만 반나절이 걸렸습니다.
문제 2: 테이블 변환
마크다운 테이블이 구글 문서 테이블로 깔끔하게 안 바뀝니다.
| 구분 | 내용 | 비고 |
|------|------|------|
| A | B | C |
이게 복붙하면 그냥 텍스트로 들어갑니다. 결국 Apps Script에 테이블 변환 로직을 추가했습니다.
문제 3: 다이어그램 (가장 고통스러웠음)
마크다운에서 다이어그램은 Mermaid 코드로 작성합니다:
flowchart LR
A[입력] --> B[처리] --> C[출력]
이걸 구글 문서에 넣으려면:
mermaid.live에서 PNG로 내보내기
그 PNG를 구글 문서에 이미지로 삽입
또는:
draw.io에서 Extras > Mermaid로 import
draw.io에서 편집 후 PNG 내보내기
구글 문서에 삽입
둘 다 수동 작업입니다.
마크다운으로 쓸 때는 Mermaid 코드 한 줄로 끝났는데, 구글 문서로 옮기면서 다이어그램 하나당 5~10분씩 걸렸습니다. 제안서에 다이어그램이 5개 있었으니 거의 1시간.
�나노 바나나도 GPT Image도 저를 구해주진 못했어요. 이건 제가 프롬프트를 잘 못쳐서 그런걸수도 있습니다만, 아무튼 시간에 쫓기고 있어서 더 시도해보지 못했습니다.
아래 머메이드 다이어그림을 16:9 사이즈로 깔끔하고 현대적이게 그려줄래?
lowchart LR
subgraph D["1. Discovery<br/>발견"]
D1["오늘의 벤치마킹<br/>추천 도착"]
D2["Implicit<br/>Personalization<br/>기반 추천"]
end
subgraph G["2. Guidance<br/>가이드"]
G1["지피터스 원본<br/>검증 사례"]
G2["AI 보강<br/>상세 가이드"]
end
subgraph E["3. Execution<br/>실행"]
E1["'3분 만에<br/>따라 해보기'"]
E2["업무 툴 자동 연동<br/>Claude / ChatGPT /<br/>Linear / Jira"]
end
subgraph F["4. Feedback<br/>피드백"]
F1["명시적 피드백<br/>라이크 / 평점"]
F2["암묵적 피드백<br/>행동 로그 수집<br/>완료·이탈·체류시간"]
end
subgraph M["5. Management<br/>관리"]
M1["팀장 대시보드"]
M2["AI 활용도<br/>완주율 / AX 지수<br/>외부 벤치마크"]
end
D --> G --> E --> F --> M
F -->|"추천 품질<br/>개선 루프"| D
<나노 바나나 작품>

<GPT Image 작품>
교훈:
제출 포맷을 처음부터 고려해서 작성해야 함
draw.io나 Canva로 처음부터 그릴 걸 그랬음
또는 Mermaid → PNG 자동 변환 파이프라인을 미리 세팅해놓을 걸
5. 총 결론: AI와 글쓰기, 무엇이 달라졌나
AI가 대체한 것
1. 포맷 맞추기
불릿 리스트 정리, 헤딩 레벨 맞추기, 표 양식 통일
이런 "생각 없이 할 수 있는 일"은 확실히 AI가 잘함
2. 초안 작성
빈 페이지 공포증 해결
일단 뭔가 채워져 있으면 수정하기 훨씬 쉬움
3. 세세한 체크
평가 기준에 나온 항목 빠짐없이 확인
숫자/출처 누락 체크
"트집 안 잡히게" 쓰는 데 도움
AI가 대체 못한 것
1. 내 생각 정리
AI가 쓴 걸 보면서 "아 이건 아닌데"라는 판단은 내가 해야 함
방향 수정, 강조점 변경 등은 사람 몫
2. 심사위원 평가 환경 or 심리 반영
"서류 평가는 꼼꼼하게 읽어보지 않을텐데, 스킴해서 볼 때 눈에 확 들어오는가?"
"심사 시에 첫 2-3분 동안 빠르게 훑어보는 심사위원 입장에서 눈에 띄는가?"
이런 건 아직 AI가 잘 못함 (하지만 프롬프트로 유도는 가능)
3. 최종 책임
AI가 쓴 숫자가 틀릴 수 있음
결국 팩트체크는 사람이 해야 함
생산성 체감
한 번 쓰는 작업: 20~30% 정도 빨라진 느낌
AI 쓰는 법 익히고, 프롬프트 다듬고, 결과 검토하는 시간이 있어서 드라마틱하지는 않음
반복 작업: 훨씬 큼
한 번 만들어둔 프롬프트, 스크립트, 참조 파일을 다음 프로젝트에 재활용
같은 형식의 제안서를 또 쓴다면 50% 이상 단축 예상
리뷰 효능감: 가장 컸음
"내가 놓친 걸 AI가 잡아줬다"는 안도감
심리적으로 제출 전 불안감 감소
6. 다음에 또 쓴다면 이렇게 하겠다
외부 문서 변환
Markdown Converter 스킬 대신 Parse 라이브러리 사용
처음부터 깔끔한 .md 파일로 만들기
리서치 타이밍
아웃라인 단계에서 리서치 완료
리서치 결과를
research-results.md같은 파일로 정리챕터 쓸 때는 그 파일만 참조
Ralph Loop 활용
전체를 한 번에 돌리지 않고, 섹션별로 돌리고 중간 확인
그걸 끝내서 원하는대로 나온다 싶고, 내 생각도 정리되면, 그때 전체를 10벌 정도 만든 후 가장 좋은 것 선택
제출 포맷 고려
처음부터 구글 문서 호환성 고려
다이어그램은 draw.io나 Canva로 처음부터 작성
또는 Mermaid → PNG 자동 변환 파이프라인 세팅
리뷰 시간 확보
AI 리뷰 피드백을 반영할 시간을 마감 2~3일 전까지 확보
이번에는 마감 직전이라 피드백 반영 못한 게 아쉬움
7. 핵심 팁 정리 (전체 시리즈 종합)
준비 단계
외부 문서(PDF, 양식 등)를 깔끔한 마크다운으로 변환해두기
딥테크 같은 모호한 기준은 실제 선정 사례에서 역추론
Task를 서브태스크로 쪼개고 PASS/FAIL 기준 정의
작성 단계
아웃라인 단계에서 리서치까지 완료하기
한 번에 다 돌리지 말고, 섹션별로 쓰고 리뷰하기
AI가 쓴 초안을 보면서 내 생각 정리하기
리뷰 단계
서브에이전트 병렬 리뷰로 다각도 검토
긴 문서는 요약+원문 조합, 또는 Gemini 병행
리뷰 피드백 반영할 시간 확보 (마감 2~3일 전)
제출 단계
처음부터 제출 포맷(구글 문서/워드) 호환성 고려
다이어그램은 Mermaid 말고 draw.io/Canva로
최종 팩트체크는 사람이
마무리: 재활용이 핵심이다
이번 프로젝트에서 만들어진 것들:
plan-write-up.md- 20개 서브태스크 정의서guide-proposal.md- 고득점 전략 가이드run-tasks.sh- 자동 실행 스크립트progress.txt- 상태 관리 파일google-apps-script/markdown-to-gdoc-style.gs- 문서 변환 스크립트각종 리서치 결과 파일들
이것들은 다음 정부과제에서 재활용할 수 있습니다.
처음 한 번은 세팅하느라 시간이 걸렸지만, 두 번째부터는 훨씬 빠르게 진행할 수 있을 겁니다. 비개발자가 AI 코딩 에이전트를 쓰는 진짜 가치는 여기에 있습니다:
"한 번 만든 워크플로우를 파일로 남기고, 다음에 재활용한다."
웹 챗봇으로는 이게 안 됩니다. 대화가 끝나면 사라지니까요. 로컬 파일 기반 에이전트를 쓰면, 내가 쌓아온 작업물이 자산으로 남습니다.
